
MonoFormer aims to build and train one transformer for both autoregression and diffusion. Examples of MonoFormer for both image generation and text generation tasks. Left: Class-conditional image generation. Middle: Text-to-image generation. Right: Text-to-text generation.
Abstract
Most existing multimodality methods use separate backbones for autoregression-based discrete text generation and diffusion-based continuous visual generation, or the same backbone by discretizing the visual data to use autoregression for both text and visual generation. In this paper, we propose to study a simple idea: share one transformer for both autoregression and diffusion. The feasibility comes from two main aspects: (i) Transformer is successfully applied to diffusion for visual generation, and (ii) transformer training for autoregression and diffusion is very similar, and the difference merely lies in that diffusion uses bidirectional attention mask and autoregression uses causal attention mask. Experimental results show that our approach achieves comparable image generation performance to current state-of-the-art methods as well as maintains the text generation capability.
Architecture
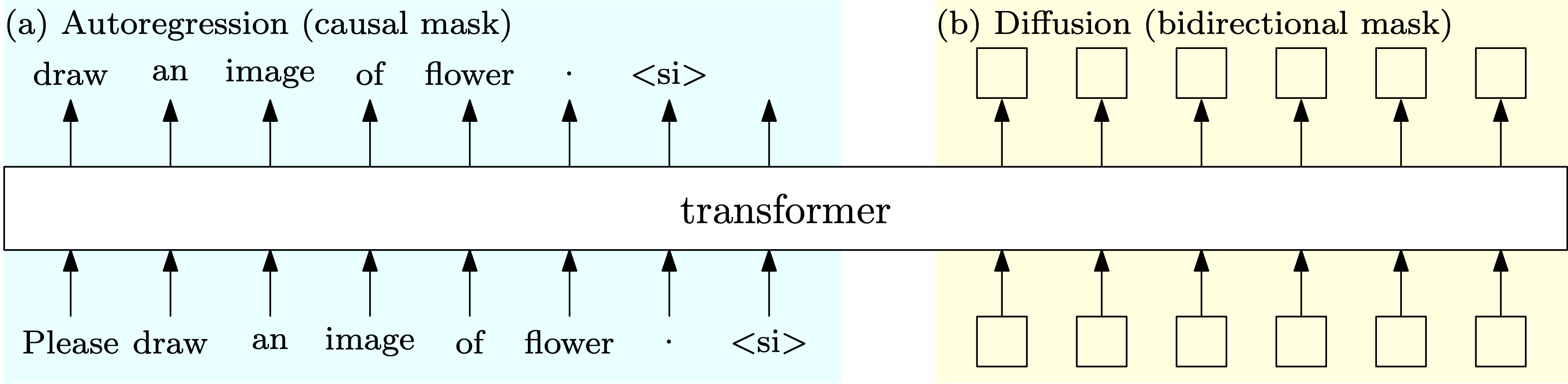
Our approach MonoFormer trains the autoregressive transformer and the diffusion transformer, which share the weights, and uses causal attention mask and bidirectional attention mask,
respectively. During training, the input of the transformer for autoregression is the text token embeddings, and the output is embeddings that are further processed for text generation. The input for
diffusion is the noised latent embeddings, and the output is embeddings that are used to predict the noise.
Quantative Experiments
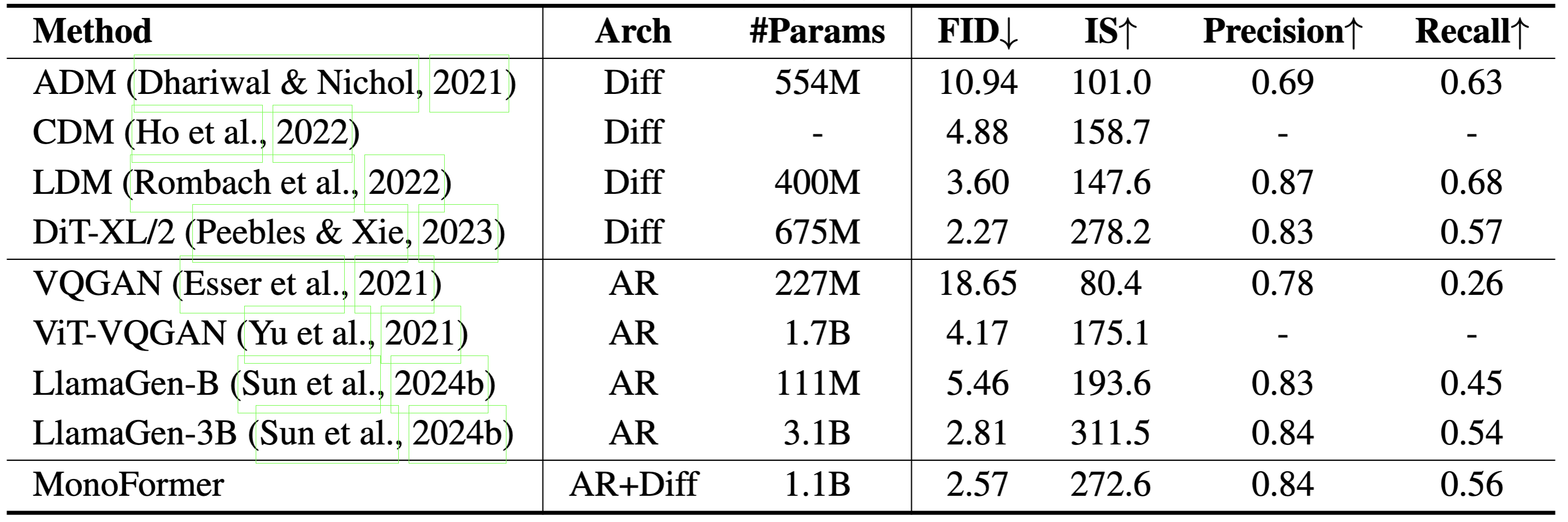
Performance on ImageNet 256×256 benchmark.

Performance on commonsense reasoning tasks.
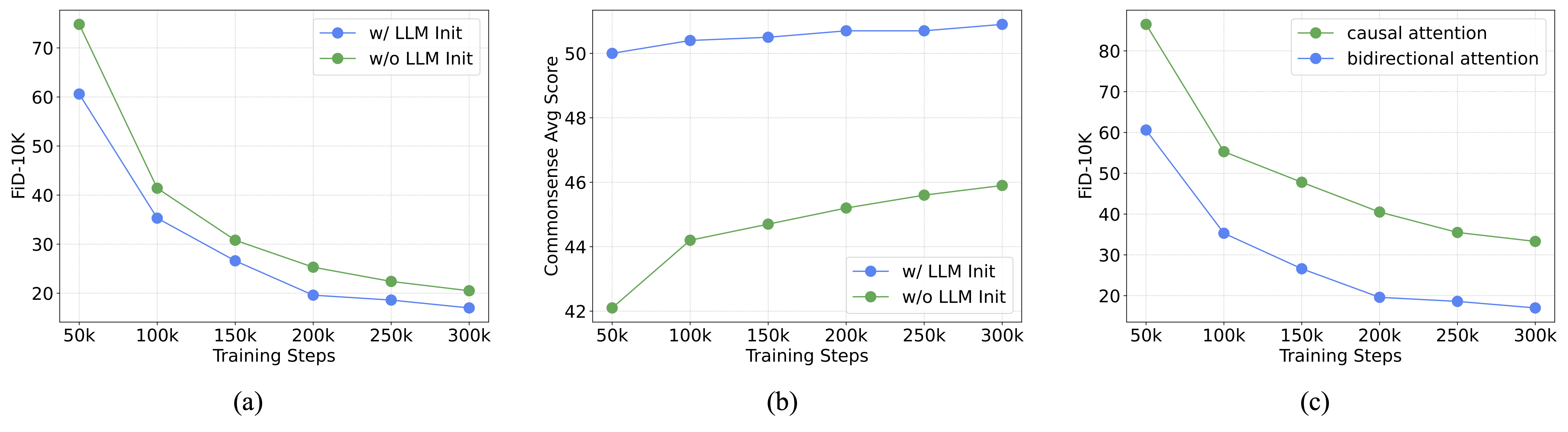
(a) The effect of transformer initialization for image generation, measured using the FiD-
10K metric on ImageNet. (b) The effect of transformer initialization for text generation, measured
by the average commonsense reasoning score. (c) The effect of bidirectional attention mask for
image generation.
Qualitative Experiments

Example results of class-conditional image generation on ImageNet.
Example results of text-to-image generation.
Paper

MonoFormer: One Transformer for Both Diffusion and Autoregression
Chuyang Zhao, Yuxing Song, Wenhao Wang, Haocheng Feng, Errui Ding, Yifan Sun, Xinyan Xiao and Jingdong Wang
Arxiv, 2024.
@article{zhao2024monoformer,
title={MonoFormer: One Transformer for Both Diffusion and Autoregression},
author={Zhao, Chuyang and Song, Yuxing and Wang, Wenhao and Feng, Haocheng and Ding, Errui and Sun, Yifan and Xiao, Xinyan and Wang, Jingdong},
journal={arXiv preprint arXiv:2409.16280},
year={2024}
}Contact
If you have any questions, feel free to contact Chuyang Zhao (zhaochuyang@baidu.com).
Acknowledgements
This template was originally made by Phillip Isola and Richard Zhang for a colorful project, and inherits the modifications made by Jason Zhang and Shangzhe Wu. The code can be found here.